[機械学習]マルチタスク学習で勾配を効率よく学習するには??NeurIPS, 2020
マルチタスク学習って夢とロマンがありますよね。
しかし、マルチタスク学習の勾配に関わる問題と解決策を考えたことがあるでしょうか?
ぼくは考えたことがまっっっっったくありませんでした。同僚が面白い論文を紹介してくれたので、紹介します。
紹介する論文はこれ"Gradient Surgery for Multi-Task Learning", Tianhe Yu et. al, 2020, NeurIPS [1] 知らないうちにNIPSからNeurIPSに名前が変わっていた。https://webbigdata.jp/ai/post-2123

この記事で紹介する内容とスクショはv4に基づきます。
まずは簡単に論文をまとめてみましょう。
マルチタスク学習の勾配学習を考えたことあるか?
タスクごとの勾配が別々の方向に行ってしまうことがよくあるんやで。
するとやぁ、解が局地最適解にハマりやすくなるんや。タスクごとの勾配方向を調整してやらなあかんのやで。
ぼくらはPCGradというのを紹介するわー。めっちゃ単純やで!
目次
マルチタスク学習の勾配問題
そもそもマルチタスク学習の勾配問題とは何でしょうか?
勾配問題といえば、こんなイメージを浮かべる人が多いと思います。

上の例は、パラメタが1次元のとき、かつ、タスクがシングルタスクのときですね。
では、パラメタを2次元にして、かつ、タスクを2つのマルチタスクにするとどうなるでしょうか?
こうなります。

task1とtask2が全く別の方向に勾配を転がってしまうことが起こりえます。この状態が起きても、モデルは1つの方向に学習しないといけないわけですから、何らかの勾配をまとめる方法が必要です。
どうすればいいんでしょう?
weight scalingだ!
マルチタスク学習でのスタンダードは、weight scalingという方法だそうです。 [2] と、聞いた。ぼくは知らないよ! weight scalingはこの論文で紹介されているそうです。が、ぼくは未確認です。
Zhao Chen, Vijay Badrinarayanan, Chen-Yu Lee, and Andrew Rabinovich. Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks. In International
Conference on Machine Learning, 2018.
Ozan Sener and Vladlen Koltun. Multi-task learning as multi-objective optimization. In
Advances in Neural Information Processing Systems, 2018.
weight scalingを簡単にいうと「重みだけでタスク間の調整する」です。くっそいい加減な理解を式にすると、こうなります。
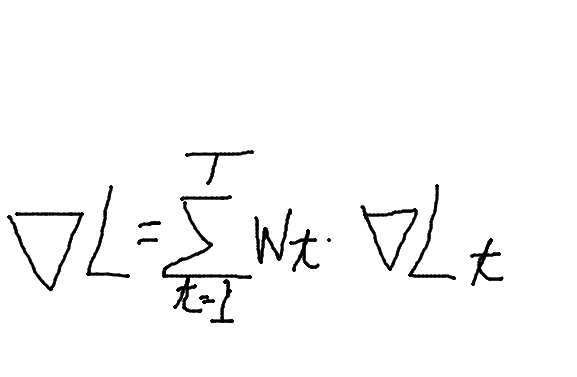
しかし、weight scalingでは、解が局所解にはまってしまいやすい問題があるそうです。高次元空間のマルチタスク空間は局所解だらけのようですね。
では、どうすればいいんでしょうか?

勾配を直接いじる
重みだけで解決なんて、ケチ臭いことは止めましょう。勾配の方向を直接に変更してやればいいんです。ということで、PCGradをこの論文は提案します。
簡単に表現すると、PCGradのアイディアは下の図のとおりです。
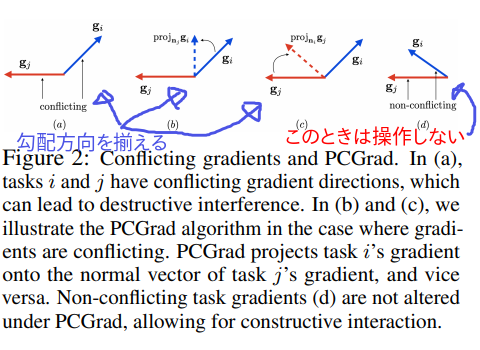
まず(d)のときは、何も操作しなくていいです。勾配方向がだいたい同じだから。
(a)の状況のとき、勾配を操作します。具体的には、(b)か(c)の操作です。
じゃあ、(d) or NOTの判定はどうすればいいんでしょう?
cosineです。なぜなら、角度を考えたいからです。cosine = 0をしきい値に(d) or NOTの判断をします。
じゃあ、次に(a)から(b) or (c)にするにはどうすればいいんでしょう?
親切にもアルゴリズムを掲載してくれています。マジ親切☆彡
青枠の部分が勾配の向きと大きさを操作してる式です。

式をみれば、操作の単純さがわかると思います。
「は?わけわかんねぇよ?」という方へ。この式は2つの要素を持ってます。1つは、勾配の大きさ調整(gradient magnitude similarity)。もうひとつは、勾配の向き調整(multi-task curvature)。

この2要素から式を導き出した過程はセクション2.4に書いてあります。 [3] ぼくは理解が甘いので、説明を避けていくー
PCGradの実力
下の図がわかりやすいです。これは強化学習での実験結果です。
紫線がPCGradです。圧倒的じゃないかっっっ!
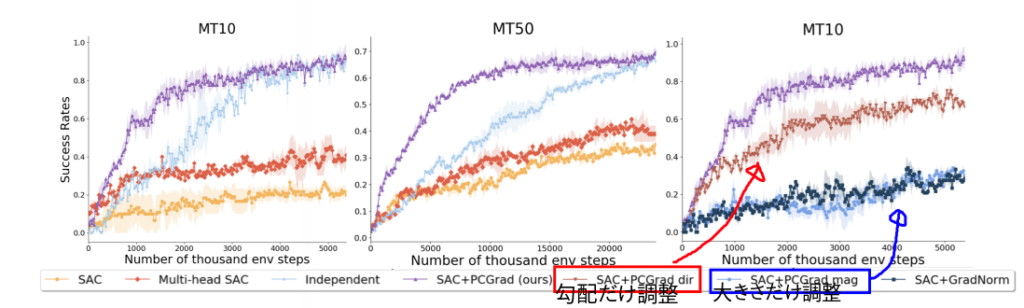
SACというのは、soft actor-critic (SAC) algorithm, an off-policy RL methodのことらしいです。強化学習のスタンダードなんでしょうか?ぼくはぜんぜん知らないです。
強化学習わかってないのに、あえてこの図を持ってきたのには意味があります。
コメントを書き込んだとおり、方向だけ調整と大きさだけ調整の2パターンの実験があります。これを言いたかった。
方向だけを調整した版(赤)の方が、大きさだけ調整した版(青)よりも良いですよね。
つまりここから言えることは、マルチタスク学習において方向操作が特に重要であるということです。
おわりに
マルチタスク学習の勾配っていう、ぼくがぜんぜん知らない世界の論文を紹介しました。
わかっていない人なりに、示唆が得られてためになった論文でした。
そして、この論文はとてもわかりやすい!英文の構成でしょうか?文書構成でしょうか?とてもスッキリと理解できる論文でした。
こういう英文を書けるように努力したいものです。
おまけ マルチタスク学習の意味とは?
別の同僚からこんな質問が出てました。
「そもそもマルチタスク学習の意味はなんだ?シングルタスク学習を独立して実行してはいけないのか?」
ぼくも考えてみたい質問です。これはきっと、方法論的な問でしょう
この質問は、本質的には次のことと同じだと思います。
「学校のテストがあります。2つのスタイルを選べます。A: 国語だけを先にテストして、1ヶ月後に社会をテスト。それぞれの教科に勉強時間を集中してとれます。 B: 国語と社会を同じ日にテストします。勉強は同時並行です。」
「さて、AとBのどちらの方が良い点数が取れるでしょうか?」
という質問と同じではないでしょうか?Aはシングルタスクの状況、Bはマルチタスクの状況です。
Aの方が良い気もしますが・・・でも、国語と社会の知識は連携していたりするものです。では、Bの方がよい??
これに絶対的な回答を出せる人はいるでしょうか?ぼくはいないと思います。
つまり、マルチタスクとシングルタスク、どっちも実験してみるのが良さそうです。